c³ 拆分可行性研究
本文将结合拆分表的定量评价一文中提出的指标,来讨论如何设计 c³ 输入方案的拆分。c³ 将会和 c⁴² 一样�是一个三拆补音的方案,以下的讨论都是基于这一前提的。
审美需求:意音拆分
汉字通常被称为「象形文字」,不过学术上更准确的称呼是「意音文字」或曰「语素文字」。「意音文字」的定义是文字中的符号(字位)可以同时表示符号的读音和含义,也就是说音、形、义三者是统一的。汉字属于意音文字,因为占字的总量的绝大多数的形声字是由意符(形旁)和音符(声旁)组成的。
- 音符一般只有一个(不过「瓩」这样的字有两个音符)
- 意符可以有一个、两个(例如「鸿」的「水」和「鸟」都是意符)
在设计形码输入法时,汉字的拆分就其定义而言当然是表形的,那么有没有可能同时表意和表音呢?请看 c42 的如下编码:
- 爱 ai 暧 bai 嫒 xai 嗳 oai 瑷 eai
- 安 an 按 jan 晏 ban 鞍 fan 桉 gan 胺 nan 铵 lan
- 执 zi 挚 zij 贽 zim 鸷 zis 絷 ziv
这些编码里,字的意符恰好对应一个编码,而字的音符的编码恰好是音符的拼音(忽略平翘舌),也是整个字的拼音。再看如下编码:
- 令 is 囹 qis 岭 wis 玲 eis 怜 yis 伶 iis 呤 ois 柃 gis 聆 his 拎 jis 冷 kis 铃 lis 蛉 cis 泠 vis 零 mis
- 台 vo 眙 qvo 殆 evo 怡 yvo 诒 uvo 绐 svo 苔 hvo 抬 jvo 冶 kvo 跆 zvo 始 xvo 治 vvo 胎 nvo 贻 mvo
虽然「令」的拼音不是 is,「台」的拼音也不是 vo,但是在这些字里用于表示字的音符的编码是统一的。换句话说,is 和 vo 在这里就起到了表音的作用,在输入这些字的时候,是类似于「双拼 + 辅助码」的体验,只不过这里的双拼并不对应现代汉语的语音。下面我们给出「意音拆分」的定义:
意音拆分:汉字的意符和音符在拆分和编码中有相对固定的表示,从而拆分不仅表形,还表音和表意。
乍一看这个特点是很容易被满足的,只要按顺序拆分意符和音符就可以了。但是,对于三码方案而言,实现意音拆分有一定的挑战性,因为总的拆分数量很可能大于三。例如,在「首、二、末」的取码规则下,可能会出现:
- 意符的完整性问题:假设「糸」不是字根,那么「紊」中它会被二拆,但在「繁」中它只会取到最后一码「小」
- 音符的完整性问题:假设「鼠」不是字根,那么「溪」中的「奚」取为「爫、大」,但「鼷」中只取到「大」
因此,三码方案中意符需要尽可能作为字根,音符需要尽可能在两拆中拆完,才能保证比较好地实现意音拆分。在现有的输入方案中,山人和虎码比较好地照顾到了意符的完整性,可以作为参考,不过音符的完整性目前还没有太多人研究过。
易学需求:提高递归性和连续性
在拆分表的定量评价中我们定义了递归性和连续性作为拆分的指标。先考虑连续性。在三拆的情况下,取末码导致的不连续的情况明显增多,而且这种不连续在末根不是在右下角的时候尤为不直观,例如
- 「惕」的末根是「两撇」
- 「蝎」的末根是「折」
- 「僦」的末根是「点」
再考虑递归性,因为同一个部件在字中可能在前面出现也可能在后面出现,例如「蟹、懈、邂」等,取末码会导致取法不一样。
综上所述,对于三拆的情况,「首、二、末」可能并不是最好的办法。意音拆分和递归性要求必须考虑到汉字自然分部的因素,连续性则要求我们尽可能顺序取码。因此,如果能基于顺取和分部来设计新的取码方法,在不引起太多歧义的情况下使得递归性和连续性得分明显优于「首、二、末」,那么就可以认为这是更好的取码方法。
对于分部,目前看到研究最透彻的是张码,所以先向张码借鉴一些术语。
- 左右、左中右结构称为「并型」
- 上下、上中下结构称为「叠型」
- 各种包围、半包围结构统称「围型」
- 如果「叠型」中的一部分是左右结构,那么称这部分为「叠眼」,这个叠型称为「眼叠」
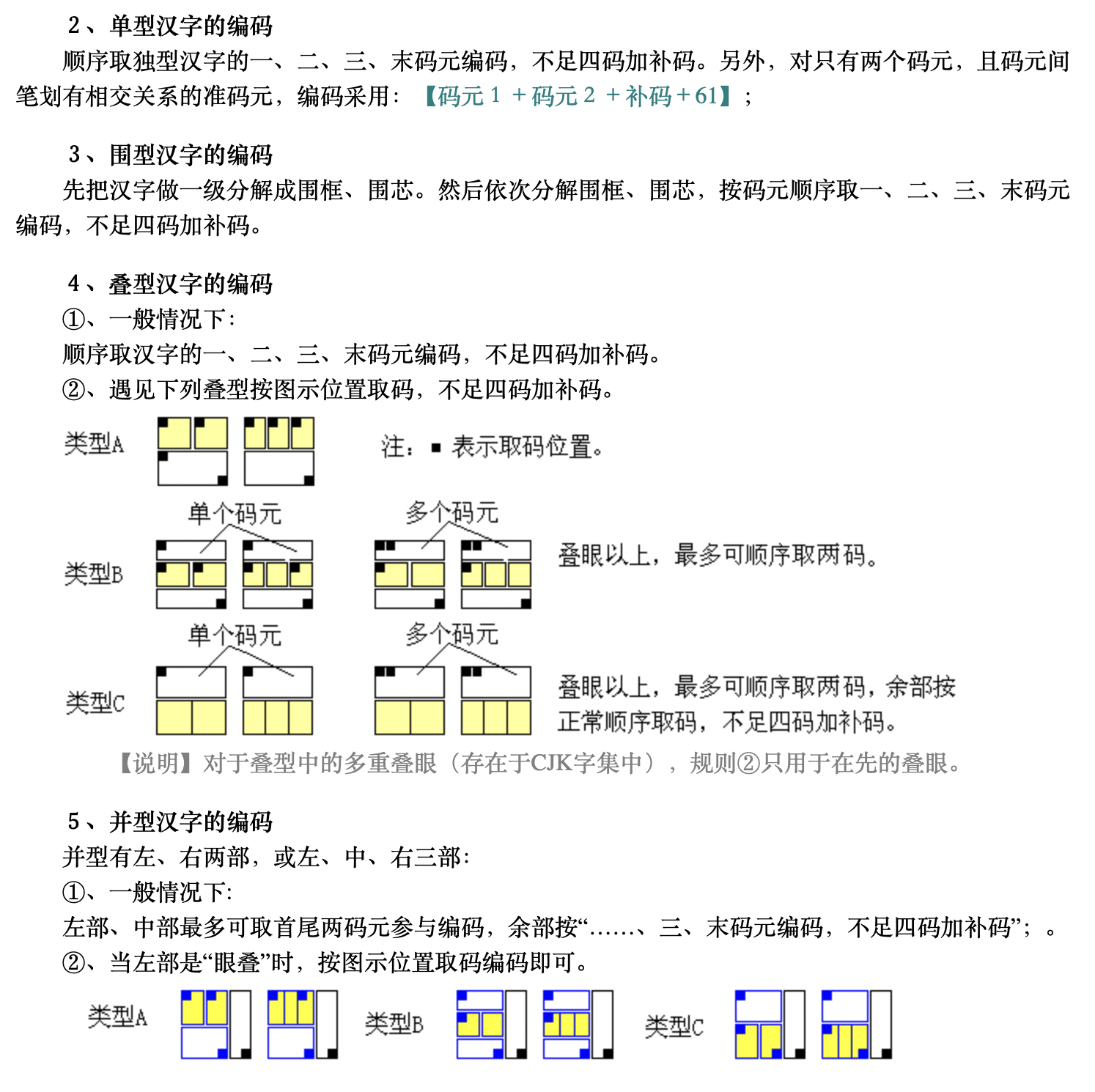
可以看到这种规则的优点在于单型、围型和一般叠型(非「眼叠」)的规则是统一的,都是「首、二、三、末」。用过二笔类方案的都知道,汉字大多数分部的歧义都在于叠型汉字,所以一般叠型顺取已经解决了大部分歧义。但是缺点在于涉及到「眼叠」时规则复杂,而且对于并型汉字的处理既需要分部,又需要首末,相当于两种思维并存。不过好在 c³ 是三拆方案,可以对其中的大多数情况合并或简化。
暂定的规则
首先定义「块」的概念:
- 单型是一块;
- 围型是内外两块;
- 叠型如果没嵌套其他并型和围型也是一块;如果嵌套了其他并型和围型,则可以沿那个界限分块;
- 并型是左右两块或者左中右三块
然后定义「分块」的概念:一个字最多分两次,如果第一次就分为了三块就不再分了,如果第一次分为两块则这两块可以再分一次。
最后取码:三块及以上,前三块各取一根;两块,每块最多取前两根;一块,最多取前三根。
二三同构性
「二三同构」是指,有些字在字形上是三分,但是在形声字的意义上是两分。如果分部取码的规则不管是按三分还是两分得到的结果都一样,那么就是二三同构的。
上述规则是二三同构的,因为如果一开始是按二分来看,那么后面还可以继续分。但是一般的二笔的规则不是二三同构的,因为二笔不会对首部再分。
离散需求
参照拆分表的定量评价,尽量减小二元边际分布和一元边际分布上的方差即可。在分部取码的前提下,这应该不难。
不过有一点比较矛盾:以音符「青」为例,部首在前、「青」在后的情况在通用规范汉字 8105 字中就足有 21 个。如果「青」是二拆,那么 ,这个对离散很不利。如果「青」是字根,那么倒是可以通过补音的方式来离散开,但这样意音拆分的统一性就降低了,因为补的声母可能是 q, j, c 等等,并不确定。这种情况还需要进一步权衡。